🔥[2024-05-10]: The pretraining code has been released, and we also invite you to follow Neo.
We introduce CT-LLM, a 2B parameter language model, marking a shift towards focusing on the Chinese language for LLM development. Starting from scratch, CT-LLM primarily uses Chinese data from a 1,200 billion token corpus, including 800 billion Chinese, 300 billion English, and 100 billion code tokens. This mix enhances its Chinese processing abilities, further improved by alignment techniques. CT-LLM shows excellent performance in Chinese language tasks on the CHC-Bench and is also adept in English through SFT. This approach challenges the norm of relying on English corpora for LLM training, expanding training methodologies. By open-sourcing CT-LLM's training process, including data processing and the Massive Appropriate Pretraining Chinese Corpus (MAP-CC), and introducing the Chinese Hard Case Benchmark (CHC-Bench), we encourage further research and innovation, aiming for more inclusive and adaptable language models.
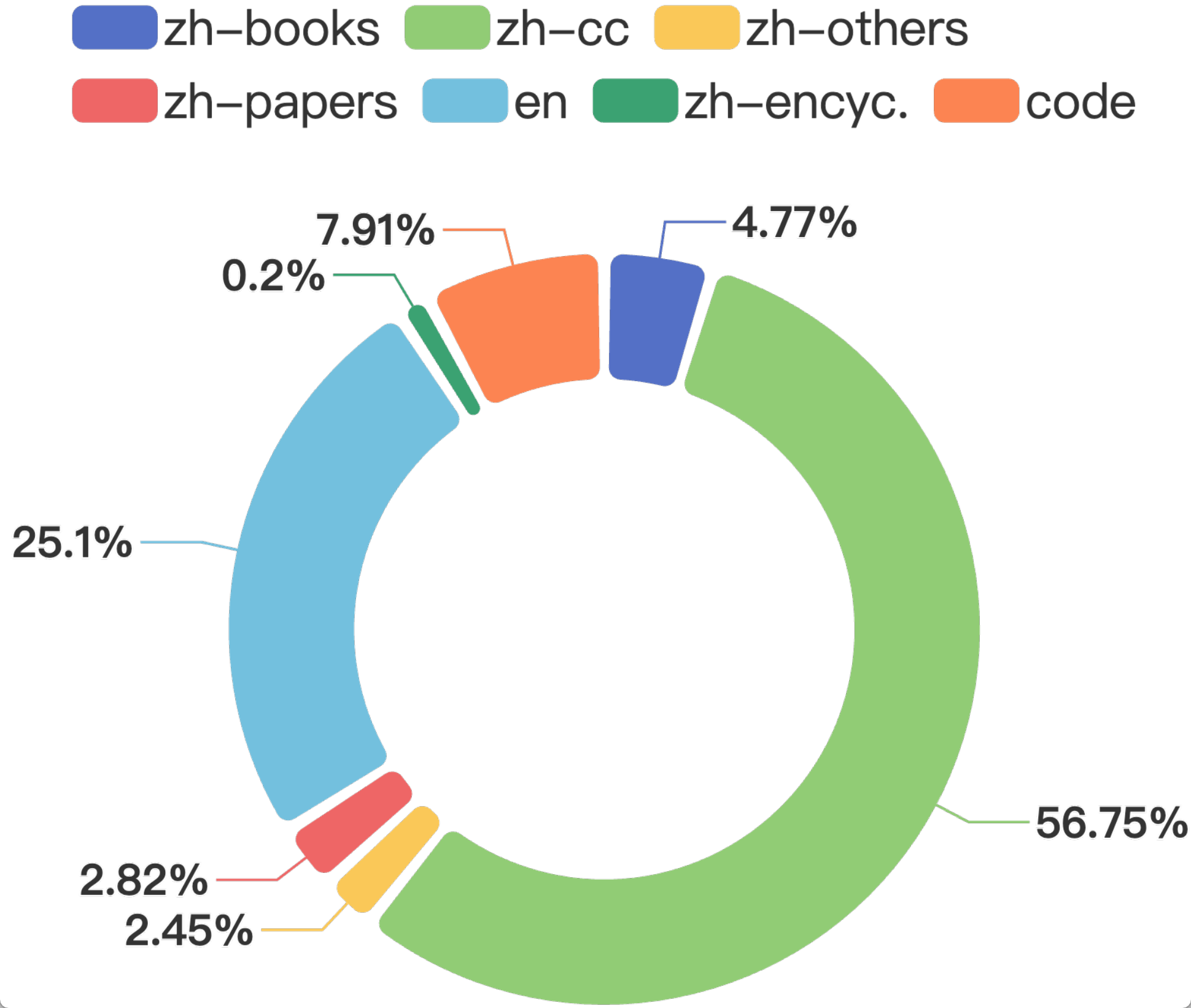
The diversity and comprehensiveness of the dataset are crucial for training a large language model for a general domain. Guided by the aforementioned principles and our emphasis on utilizing Chinese corpora for model training, we have developed a dataset encompassing 1,254.68 billion tokens. This dataset integrates Chinese, English, and code data, consisting of 840.48 billion Chinese tokens, 314.88 billion English tokens, and 99.3 billion code tokens. The dataset aggregates content from diverse sources, such as web documents from Common Crawl, scholarly articles, encyclopedias, and books.


Our model's architecture is based on the transformer decoder. The key parameters that define our architecture are shown in Table 1, with the models being trained on a substantial context length of 4096 tokens. Beyond the foundational elements, our approach integrates several improvements compared to the original transformer.
Why CHC-Bench is hard for LLMs. CHC-Bench tests LLMs on their deep understanding of Chinese culture, history, traditions, as well as humanities, geography, and STEM, all within the Chinese context. It includes tasks that require knowledge of Chinese literary traditions, such as poetry and couplet writing, ancient Chinese comprehension, pronunciation mastery, and explanation of terms. LLMs trained mainly on English data might struggle with these tasks compared to English benchmarks like MTbench. Models with limited Chinese training data, like TinyLlama-1.1B-Chat, Deepseek-coder-1.3b, and Bloom-1.7b, often score below 3.00 in categories involving Chinese cultural and language understanding. For STEM, the assessment focuses on various difficulty levels, especially on Chinese high school subjects like math, physics, chemistry, biology, and coding, requiring understanding of Chinese commands.
| Category | Subcategories | Total Questions |
|---|---|---|
| Writing | Official documents, Advertisement Writing, Poetry and couplets, Creative writing | 33 |
| Humanity | Historical common sense, Geography(Gaokao), History (Gaokao) | 20 |
| Science | Physics(Gaokao), Chemistry(Gaokao), Biology(Gaokao) | 20 |
| Role-playing | 20 Characters including Batman, Wukong, etc. | 20 |
| Reading Comprehension | Chinese language (Gaokao), Information understanding, Argument analysis | 30 |
| Math | Elementary math, Middle school math, Math (Gaokao), College math | 34 |
| Hard Cases | Ancient Chinese Language(Gaokao), Chinese pronunciation(Gaokao), Popular Chinese terms | 37 |
| Coding | Chinese command code generation, Code translation, Code annotation, Debugging | 20 |
| Dataset | 13.3B | 39.9B | 66.7B | 93.3B | 200B | 306.6B | 400B | 506.6B | 599.9B | 706.6B | 800B | 906.6B | 999.9B | 1106.5B | Final |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Standard Benchmarks | |||||||||||||||
| BoolQ | 51.74 | 44.04 | 43.98 | 48.1 | 39.97 | 43.7 | 41.87 | 39.69 | 43.39 | 52.29 | 44.53 | 45.69 | 43.73 | 52.29 | 42.17 |
| CB | 42.86 | 50.00 | 50.00 | 50.00 | 50.00 | 50.00 | 50.00 | 50.00 | 50.00 | 50.00 | 50.00 | 50.00 | 50.00 | 50.00 | 51.79 |
| COPA | 47 | 52 | 54 | 52 | 55 | 57 | 56 | 61 | 60 | 61 | 56 | 59 | 59 | 60 | 59 |
| RTE | 48.38 | 51.26 | 51.62 | 55.23 | 51.99 | 54.87 | 52.71 | 50.9 | 51.26 | 54.51 | 49.46 | 53.07 | 53.79 | 52.71 | 53.07 |
| MultiRC | 57.01 | 57.26 | 57.26 | 57.22 | 57.26 | 57.22 | 57.22 | 57.22 | 57.22 | 57.22 | 57.22 | 57.24 | 57.22 | 57.22 | 57.24 |
| WiC | 50.31 | 50.47 | 52.82 | 50.16 | 50.47 | 50 | 50.31 | 50 | 50.16 | 49.84 | 49.84 | 49.84 | 50 | 49.69 | 49.84 |
| Piqa | 58.38 | 64.69 | 65.34 | 67.25 | 68.23 | 68.12 | 68.88 | 69.75 | 69.37 | 69.26 | 70.18 | 70.73 | 70.46 | 70.29 | 70.73 |
| Siqa | 36.9 | 38.43 | 39.3 | 40.53 | 41.25 | 41.15 | 41.91 | 41.45 | 41.66 | 41.86 | 41.15 | 43.5 | 42.68 | 43.14 | 41.97 |
| Hellaswag | 26.5 | 33.3 | 36.48 | 38.72 | 42.79 | 44.67 | 45.55 | 46.77 | 47.55 | 47.81 | 48.51 | 49.16 | 49.62 | 49.87 | 50.37 |
| Winogrande | 50.59 | 52.49 | 52.09 | 52.25 | 52.17 | 53.75 | 53.43 | 55.64 | 55.01 | 54.85 | 56.67 | 56.43 | 56.43 | 55.56 | 58.01 |
| ARC-e | 28.22 | 39.15 | 43.92 | 43.74 | 47.09 | 49.21 | 50.97 | 47.8 | 47.27 | 49.74 | 51.32 | 51.15 | 51.85 | 50.97 | 50.44 |
| ARC-c | 21.02 | 22.71 | 21.36 | 20.34 | 23.39 | 25.08 | 26.44 | 26.44 | 25.76 | 27.46 | 27.46 | 27.46 | 27.12 | 27.12 | 29.15 |
| OBQA | 23.4 | 22.2 | 25.4 | 25.6 | 26.6 | 22.4 | 30.4 | 27.6 | 36.6 | 44.0 | 44.2 | 39.2 | 45.4 | 52.8 | 48.8 |
| CSQA | 27.93 | 35.71 | 38.41 | 38.98 | 42.83 | 44.64 | 45.7 | 45.86 | 46.68 | 46.44 | 45.62 | 48.16 | 48.4 | 48.73 | 48.57 |
| MMLU-Avg | 26.15 | 26.09 | 26.49 | 27.11 | 26.77 | 26.68 | 27.78 | 29.8 | 32.17 | 33.47 | 30.55 | 35.42 | 33.81 | 35.59 | 37.11 |
| *-humanities | 25.51 | 25.35 | 26.38 | 27.34 | 25.6 | 27.54 | 27.82 | 30.65 | 31.34 | 32.91 | 32.47 | 34.73 | 33.26 | 35.53 | 38.62 |
| *-stem | 26.5 | 25.33 | 26.6 | 27.74 | 26.6 | 26.4 | 27.93 | 29.75 | 30.98 | 33.26 | 28.95 | 33.06 | 32.29 | 32.22 | 33.93 |
| *-social-science | 27.28 | 27.97 | 27.33 | 26.8 | 25.04 | 25.78 | 27.35 | 29.33 | 33.55 | 35.39 | 30.28 | 39.02 | 37.22 | 37.92 | 39.52 |
| *-other | 25.24 | 26.21 | 25.68 | 26.27 | 29.77 | 27.07 | 27.89 | 29.44 | 33.46 | 32.58 | 31.23 | 36.23 | 33.42 | 38.42 | 38.05 |
| Code Generation | |||||||||||||||
| Humaneval | 0.61 | 1.83 | 1.83 | 2.44 | 9.15 | 4.27 | 6.71 | 5.49 | 8.54 | 5.49 | 9.15 | 6.1 | 8.54 | 7.32 | 9.15 |
| MBPP | 0 | 1.2 | 1 | 2.4 | 2.8 | 4.8 | 5 | 4 | 5.2 | 6.2 | 4 | 7.2 | 5.6 | 6.8 | 6.4 |
| World Knowledge | |||||||||||||||
| Nq | 0.17 | 0.3 | 0.14 | 0.22 | 0.36 | 0.78 | 1.55 | 0.94 | 0.61 | 0.72 | 0.97 | 0.94 | 0.64 | 0.47 | 0.91 |
| Triviaqa | 11.33 | 13.53 | 13.45 | 15.36 | 17.11 | 18.9 | 16.23 | 16.74 | 18.52 | 19.55 | 18.9 | 16.91 | 17.14 | 21.77 | 21.03 |
| Pretraining | |||||||||||||||
| Lambada | 19.48 | 34.37 | 43.2 | 42.85 | 45.51 | 50.2 | 51.81 | 51.64 | 53.76 | 55.89 | 53.56 | 51.87 | 54.9 | 56.3 | 56.24 |
| Reading Comprehension | |||||||||||||||
| Squad2.0 | 0.52 | 7.3 | 6.36 | 9.31 | 21.76 | 19.02 | 11.24 | 26.91 | 11.91 | 10.3 | 20.21 | 14.01 | 13.54 | 5.73 | 18.87 |
| Exams | |||||||||||||||
| GSM8k | 1.74 | 1.14 | 1.06 | 2.05 | 4.02 | 4.93 | 5.08 | 6.44 | 6.22 | 6.14 | 7.35 | 7.88 | 9.25 | 7.88 | 8.87 |
| TheoremQA | 0 | 0.12 | 0 | 0.5 | 1.88 | 2.75 | 2.25 | 1.12 | 2.75 | 0.88 | 1.88 | 0.62 | 1.62 | 0.5 | 2.12 |
| Chinese | |||||||||||||||
| C-Eval-Avg | 27.89 | 22.53 | 25.63 | 23.07 | 26.83 | 23.68 | 27.37 | 26.4 | 30.46 | 32.39 | 32.66 | 36.05 | 36.49 | 36.99 | 36.78 |
| *-stem | 28.93 | 22.78 | 25.15 | 22.84 | 23.69 | 22.37 | 23.83 | 22.96 | 26.25 | 25.79 | 27.69 | 30.77 | 32.51 | 33.66 | 33.93 |
| *-social-science | 25.75 | 23.03 | 34.49 | 24.6 | 31.24 | 24.27 | 30.66 | 28.97 | 37.13 | 41.04 | 40.75 | 41.91 | 43.44 | 43.9 | 43.05 |
| *-humanities | 29.66 | 22.25 | 17.71 | 23.19 | 26.43 | 26.13 | 26.22 | 27.66 | 28.96 | 36.84 | 34.29 | 39.71 | 38.02 | 37.55 | 35.75 |
| *-other | 26.19 | 21.89 | 26.38 | 21.97 | 28.95 | 23.06 | 31.98 | 29.07 | 33.56 | 32.08 | 32.7 | 36.66 | 35.87 | 36.22 | 37.31 |
| *-hard | 31.23 | 23.96 | 28.1 | 24.23 | 20.65 | 21.43 | 19.69 | 24.43 | 19.84 | 22.47 | 21.38 | 25.42 | 27.07 | 26.26 | 28.36 |
| CMMLU-Avg | 25.51 | 25.24 | 25.17 | 24.83 | 24.7 | 25.59 | 27.95 | 29.84 | 30.42 | 31.33 | 32.14 | 32.86 | 35.56 | 36.97 | 36.4 |
| *-humanities | 25.21 | 24.89 | 25 | 24.17 | 24.74 | 25.62 | 28.49 | 31.03 | 31.65 | 32.66 | 32.36 | 34.3 | 37.46 | 38.2 | 38.97 |
| *-stem | 25.14 | 24.59 | 25.18 | 25.41 | 24.48 | 25.56 | 25.36 | 27.17 | 27.72 | 27.71 | 28.62 | 28.75 | 30.27 | 30.63 | 31.08 |
| *-social-science | 26.17 | 25.93 | 24.88 | 24.58 | 25 | 26.04 | 29.83 | 31.15 | 30.68 | 32.84 | 34.7 | 34.75 | 37.57 | 40.05 | 37.97 |
| *-other | 25.21 | 25.27 | 25.73 | 25.1 | 24.47 | 24.94 | 27.67 | 29.91 | 32.02 | 32.09 | 32.17 | 33.48 | 36.95 | 38.57 | 37.89 |
| *-china-specific | 26.06 | 25.32 | 24.86 | 24.22 | 24.73 | 25.12 | 28.78 | 29.7 | 30.32 | 32.79 | 32.98 | 34.66 | 36.87 | 38.99 | 38.8 |
| Model | COPA | Hellaswag | MMLU | Humaneval | Triviaqa | Lambada | Squad2.0 | GSM8k | C-Eval | CMMLU |
|---|---|---|---|---|---|---|---|---|---|---|
| Qwen1.5-1.8B | 53.0 | 55.99 | 47.06 | 18.9 | 31.15 | 56.39 | 30.06 | 35.1 | 59.38 | 57.1 |
| TinyLlama-1.1B | 51.0 | 54.47 | 25.89 | 8.54 | 31.27 | 59.71 | 20.85 | 5.36 | 26.16 | 25.04 |
| Stablelm-3b-4e1t | 61.0 | 69.08 | 45.42 | 15.85 | 50.54 | 70.35 | 36.44 | 10.92 | 31.71 | 31.48 |
| Gemma-2b | 64.0 | 64.96 | 41.84 | 9.15 | 46.42 | 63.38 | 6.86 | 22.14 | 31.25 | 31.11 |
| Phi-2 | 72.0 | 67.74 | 57.62 | 0.0 | 41.04 | 62.7 | 34.81 | 61.41 | 31.53 | 32.19 |
| CT-LLM(Ours) | 59.0 | 50.37 | 37.11 | 9.15 | 21.03 | 56.24 | 18.87 | 8.87 | 36.78 | 36.4 |
| Model | COPA | Hellaswag | MMLU | Humaneval | Triviaqa | Lambada | Squad2.0 | GSM8k | C-Eval | CMMLU |
|---|---|---|---|---|---|---|---|---|---|---|
| MiniCPM-2B-sft-fp32 | 66.0 | 65.88 | 53.87 | 45.12 | 36.23 | 60.62 | 40.52 | 55.8 | 49.14 | 51.0 |
| Gemma-2b-it | 60.0 | 56.68 | 37.71 | 0.0 | 29.0 | 55.91 | 18.46 | 15.69 | 32.3 | 33.07 |
| TinyLlama-1.1B-Chat-v1.0 | 48.0 | 56.64 | 25.33 | 4.88 | 32.31 | 61.09 | 12.89 | 3.72 | 24.51 | 24.92 |
| Bloom-1.7B | 57.0 | 44.45 | 27.38 | 0.0 | 18.73 | 48.36 | 8.68 | 1.44 | 22.93 | 24.51 |
| Deepseek-coder-1.3B-instruct | 51.0 | 37.0 | 28.55 | 43.29 | 10.85 | 35.32 | 28.85 | 8.79 | 28.33 | 27.75 |
| Qwen1.5-1.8B-Chat | 57.0 | 55.75 | 45.86 | 6.71 | 24.31 | 48.83 | 47.25 | 28.73 | 56.84 | 54.11 |
| Stablelm-zephyr-3B | 64.0 | 67.94 | 46.15 | 24.39 | 33.48 | 57.46 | 21.19 | 57.01 | 29.5 | 32.11 |
| CT-LLM-SFT(Ours) | 60.0 | 52.93 | 39.95 | 10.37 | 22.88 | 51.93 | 35.18 | 19.18 | 41.54 | 41.48 |
| CT-LLM-SFT-DPO(Ours) | 61.0 | 53.38 | 39.82 | 7.93 | 23.64 | 51.47 | 31.36 | 18.5 | 41.18 | 42.01 |
This model, developed for academic purposes, employs rigorously compliance-checked training data to uphold the highest standards of integrity and compliance. Despite our efforts, the inherent complexities of data and the broad spectrum of model applications prevent us from ensuring absolute accuracy or appropriateness of the model outputs in every scenario.
It is essential to highlight that our model and its associated training data are intended solely for scholarly research. We explicitly disclaim any liability for problems that may arise from improper use, interpretation errors, unlawful activities, the dissemination of false information, or any data security issues related to the utilization of our model or its training data.
We strongly encourage users to report any concerns related to data misuse, security breaches, or potential infringement issues directly to us for immediate investigation and resolution.
Contact: ge.zhang@uwaterloo.ca; duxinrun2000@gmail.com
Our commitment to responsible data sharing and the security of our academic tools is paramount. We thank you for your cooperation in maintaining the ethical use of this technology.
The MAP-CC Dataset is made available under the terms of the Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License (CC BY-NC-ND 4.0 License).
By using the MAP-CC Dataset, you accept and agree to be bound by the terms and conditions of the CC BY-NC-ND 4.0 License. This license allows users to share (copy and redistribute the material in any medium or format) the MAP-CC Dataset for non-commercial purposes only, and with no modifications or derivatives, as long as proper attribution is given to the creators. For further details, please refer to the LICENSE file.
We chose the CC BY-NC-ND 4.0 License for the MAP-CC Dataset to facilitate academic and educational use, promoting the spread of knowledge while protecting the work of the creators from unauthorized commercial use or modification.
@misc{du2024chinesetinyllmpretraining,
title={Chinese Tiny LLM: Pretraining a Chinese-Centric Large Language Model},
author={Xinrun Du and Zhouliang Yu and Songyang Gao and Ding Pan and Yuyang Cheng and Ziyang Ma and Ruibin Yuan and Xingwei Qu and Jiaheng Liu and Tianyu Zheng and Xinchen Luo and Guorui Zhou and Wenhu Chen and Ge Zhang},
year={2024},
eprint={2404.04167},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2404.04167},
}